
On token economics
It's clear today that inference is broadly priced below cost. What will hopefully become clear as we see Anthropic and OpenAI's IPOs is "how far below cost?"
The optimistic case, based on what Anthropic has released thus far, is that you're paying $0.6-0.7 for every $1 of compute.
The pessimistic case figures that hyperscaler capex, private credit, circular transactions, and the tax code are each acting as another layer of subsidy. They conclude that you may be paying less than $0.1 for every $1. They also don’t see demand plateauing. While I don't disagree on any particular point, I find the argument that demand will increase exponentially beyond the point where customers can't afford the product to be a bit circular itself.
I can only speculate on how the inevitable re-pricing will affect the industry in the medium term.
If the optimists are right, then Moore's law and cheap solar panels might get us over the bump with customers barely noticing.
If the pessimists are even half right, you're going to see demand destruction. But the impact will be heavily use case dependent.
Even assuming a $4k/month Claude bill, I don't think you're going to see "junior coders being hired to write simple snippets of code because LLMs have gotten so expensive that it makes financial sense to treat humans like LLMs". Only the worst companies will pull a high performer into a room and discuss how they ran up $4,100 in token usage, when the average performer next to them got away with $3,900. However, good companies will still care about the token economics of your deployed AI-dependent workflows in production [related how-to post]. To put this in 2010 terms, you wouldn't balk at a senior engineer asking for 12GB RAM rather than 8; you would balk at their SQL query eating 12GB of RAM 10 times a day on production, when an hour of effort would have yielded a refactor that'd get it down to 8.
Outside the tech sector, I think many AI use cases will vanish in the medium term* regardless of what prices do. Normal people are not going to pay $200 or even $20 a month for an agent to make their restaurant reservations; that use case might work at $2, but price matters more here.
On use cases and the long-term
If there's one thing I could impart to my mostly tech-heavy and AI-positive peer group, it's how much people outside of it hate the technology. Polling tells us that AI is about as popular on college campuses as a System of a Down concert would be in a retirement community. The media is focused on the "it's gonna take my job" aspect, but in my experience it's more mundane: plumbers are annoyed that their email app wants to reply with hallucinated dates and times they [actually can't] make an appointment, nurses are annoyed that the blouse they ordered didn't look anything like how it looked on the AI-generated model, and normal people just call "feature discovery moments" or "coach marks" what they are: "popup ads".
I say "medium term" here, because I think machine learning - LLMs or the next thing - are not going away. The question is how hard you have to squint to make the thing that eventually addresses the use case in 2045 look like the thing no one wants today.
You may have been tempted to look at Webvan and Flooz and say, “no one wants to buy groceries on the internet” or “people don’t trust online money”. The predictions about those companies were correct even as the words aged poorly.
By “No one wants their AI avatar to go on a date with anyone else's AI avatar” … What we mean isn’t “There will never be an artificial neural net in a successful dating app” … it’s “no one is paying for the goofy trash that’s on offer.“
A knave might babble about timing, but for those of us in the industry, it's not timing, it's execution. If you're not making the product or experience better or cheaper, the "technology" doesn't matter. “Pets.com was just too early” is an amateurish take.
Squaring the circle
Ultimately, if it turns out there’s no way to make the numbers add up for derided tools like Google’s AI summary or Copilot (Windows not GitHub), that loss of demand will ease price pressures on the more sensible use cases.
While I would not completely discount the possibility that a bursting bubble leaves so many orphaned data centers that the cost of inference actually declines toward the cost of electricity, I think data center construction takes long enough that most of those hypothetical excess data centers wouldn’t come online.
On the consumption side - it’s clear that there’s lots of room to do more with less:
Models could be more efficient while sacrificing little ability
APIs route queries intelligently to cheaper models
Consumers today waste tokens because they have little incentive not to. See https://www.scoutcorpsllc.com/blog/2026/5/18/one-weird-trick-to-drastically-reduce-your-token-usage
LLMs currently spend a lot of cycles on tasks that could be accomplished with simple code like regexes; the industry broadly understands this and is actively working on it
On tech jobs and productivity
AI is not a replacement for an engineer - most of the time. I’ll reference this chart, if you’re tempted to blame the past few years’ layoffs on LLMs:
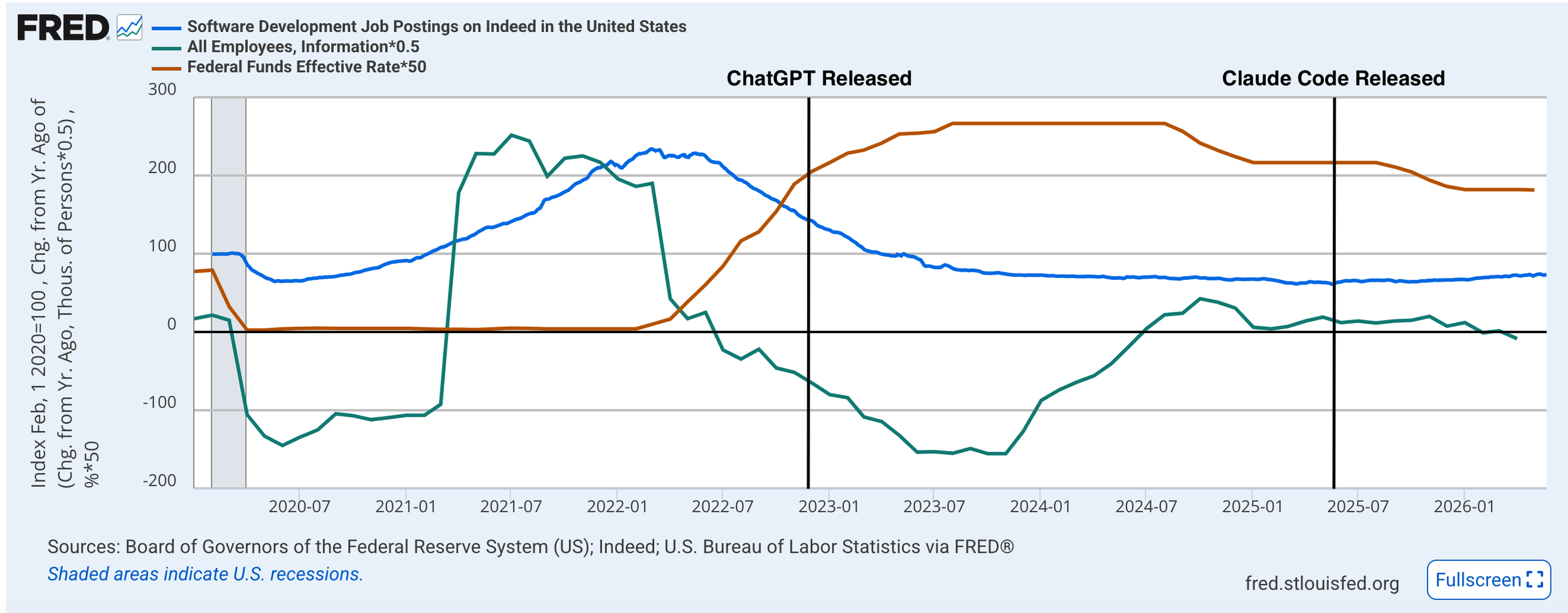
A few caveats, here
The fact that LLMs didn’t cause the noted decrease in tech hiring doesn’t necessarily mean that they won’t in the future, or at least be a tailwind
“Not a replacement” doesn’t mean “not a substitute” - more on this later
LLMs certainly reduce the lift required for many engineering tasks. On average, a good coding assistant might make a good engineer 20-30% more productive.
It’s popular to claim 10x, even 100x, but no research bears that out. I find that while some specific tasks are sped up by orders of magnitude, others are barely affected at all. Much of the temptation to say “10x+” in my experience comes from:
Type a few prompts
The LLM works all day and generates 50,000 lines of code
You say “wow! that would have taken me weeks!”
You don’t stop to realize that 48,000 of those lines are actually an almost verbatim re-type of an open-source package, with bugs introduced, that you would have found on Google or StackOverflow in 15 minutes had you been forced to look
A popular story that made the rounds a few months ago was “an LLM wrote a web browser in one week, completely autonomously! It’s buggy but it works.” I won’t deny that it’s an impressive demo, but in a practical sense … what was accomplished? We trained on every open-source web browser ever written to produce a version of “git clone firefox” that’s orders of magnitude more expensive, slower, and buggier.
My final observation on productivity is going to again be to ask the non-tech consumer. If LLMs were driving a productivity explosion, we’d see a vast array of new apps and better faster cheaper services. But most people do not believe the internet is getting better. They’re not happier with their apps than they were 5 years ago. Opinions of the tech industry have only gone down. Again, it’s mundane: the industry is talking Skynet; gamers simply think AAA studios’ AI art looks tacky.
In the day-to-day
For simpler tasks, you might be able to get away without knowing how to code at all. Then again, you could have said the same thing about WordPress or Shopify and those tools’ effect on web developers. Tools like that did drastically reduce the need for programming expertise in order to make a lot of websites, or do e-commerce! But web developers are, of course, still around.
LLMs more drastically expand the universe of apps that can be built without coding expertise beyond prior generations of low-code / no-code tools, of course. Even complex applications can often be built by a principal who has technical but non-coding expertise - people with financial, or physical engineering, or chemistry expertise build some really good stuff with LLMs and without touching “raw” code.
Cool! You’re doing software engineering at the next higher level of abstraction.
Prior to LLMs, our industry has seen a lot of technologies that made our work 20-30% faster - front-end frameworks, cloud computing, infrastructure as code, CI/CD. While the job of “manually copying the compiled code to each production server and then running the SQL migrations” is gone, DevOps is alive and well.
Substitution versus replacement
Imagine a pre-industrial revolution textile worker saying, "The mechanical loom can't do what I do". You’ve probably forgotten that that worker was right.
What?
Would you show up to a wedding in an un-tailored suit you got from Temu? Even today, we have not replaced skilled clothiers … but we sure have substituted them. We haven’t automated butchers, we just eat more hamburgers.
I’m not personally confident that this is a Jevons Paradox situation. What would substitution look like in the software profession?
I do think more purpose-built software being written and less “square peg” SaaS solutions being jammed into "round hole” problems. But will the SMBs that build their own, say, project trackers rather than putting up with Trello or Monday hire engineers to do it? Or will owners and managers do it themselves?
My takeaway here is that software engineers are going to need to bring more to the table - domain expertise, data architecture, cross-domain knowledge, good judgement and taste - other than just knowing how to code. This was always true in order to get much past an entry-level role, but it’s more true now.
More software being written by non-professionals will probably mean more security vulnerabilities, less maintainable software, less backwards compatibility / more janky migrations … but also software that fits the very specific needs of “markets” that consist of a handful of people that wouldn’t have been adequately served before.
I was tempted to predict that big tech would get worse, buggier, less secure, and more expensive … I’ll make that prediction, but I don’t think Enshittification can be blamed on LLMs.
On Education and Knowledge
There are two risks I’d like to address:
Model collapse
Anti-intellectualism
Model collapse
I worry that the AI industry is eating the golden goose. For example, if translation software puts translators out of work, there won’t be any stream of high-quality translations to use as training data going forward. There will continue to be AI-produced translations, but training ChatGPT 8 exclusively on the output of ChatGPT 7 is not a recipe for a smarter model.
Anti-Intellectualism
The ability of “AI bros” to insist that they don’t need to know things because AI can do it for them is staggering.
Consider the kid in middle school who was sure they didn’t need to learn how to do arithmetic because the calculator could do it for them. The argument against this isn’t “what if you don’t have a calculator?” or “what if the calculator gets it wrong?”. Most of us truly do not need to do long division as adults with pencil and paper.
That’s not the point. The point is that learning fundamentals equips you to learn the next thing, and the next thing. We don’t expand the frontiers of knowledge if we just use tools to repeat what’s been done before.
Kids are learning how to think, problem solve, and reason when they develop an encyclopedic knowledge of dinosaurs or play Lego - regardless of whether they become paleontologists or architects.
Back to LLMs, it’s not important that I learn Portuguese or that you learn Python - it’s important that someone does, though. And it’s important that we each learn … something … or we’re never going to be … someone.